DE⫶TR -- Extending Object Detection to Panoptic Segmentation
An Extension to Object Detection using Transformers to Predict Pixel wise mask of each class.




class ConstructionPanoptic:
def __init__(self, img_folder, ann_folder, ann_file, transforms=None, return_masks=True):
with open(ann_file, 'r') as f:
self.coco = json.load(f) # Readig the json file
# sort 'images' field so that they are aligned with 'annotations'
# i.e., in alphabetical order
self.coco['images'] = sorted(self.coco['images'], key=lambda x: x['id'])
self.coco['annotations'] = sorted(self.coco['annotations'], key=lambda x: x['image_id'])
# sanity check, image names in images is same as in annotations masks.
if "annotations" in self.coco:
for img, ann in zip(self.coco['images'], self.coco['annotations']):
#print(img['file_name'], ann['file_name'])
assert img['file_name'].split('.')[:-1] == ann['file_name'].split('.')[:-1]
self.img_folder = img_folder
self.ann_folder = ann_folder
self.ann_file = ann_file
self.transforms = transforms
self.return_masks = return_masks
def __getitem__(self, idx):
ann_info = self.coco['annotations'][idx] if "annotations" in self.coco else self.coco['images'][idx]
img_ext = Path(self.coco['images'][idx]['file_name']).suffix
img_path = Path(self.img_folder) / ann_info['file_name'].replace('.png', img_ext)
ann_path = Path(self.ann_folder) / ann_info['file_name']
img = Image.open(img_path).convert('RGB')
w, h = img.size
if "segments_info" in ann_info:
masks = np.asarray(Image.open(ann_path), dtype=np.uint32) # Read the mask file
masks = rgb2id(masks) # Convert the mask to the id format
ids = np.array([ann['id'] for ann in ann_info['segments_info']]) # Get the unique ids of classes in mask
masks = masks == ids[:, None, None]
masks = torch.as_tensor(masks, dtype=torch.uint8)
labels = torch.tensor([ann['category_id'] for ann in ann_info['segments_info']], dtype=torch.int64)
target = {}
target['image_id'] = torch.tensor([ann_info['image_id'] if "image_id" in ann_info else ann_info["id"]])
if self.return_masks:
target['masks'] = masks
target['labels'] = labels
# Calculating BBox using mask, we already have BBox in annotations, we could have directly call ann_info['bbox']
target["boxes"] = masks_to_boxes(masks) # target["boxes"] = ann_info['bbox']
target['size'] = torch.as_tensor([int(h), int(w)])
target['orig_size'] = torch.as_tensor([int(h), int(w)])
if "segments_info" in ann_info:
for name in ['iscrowd', 'area']:
target[name] = torch.tensor([ann[name] for ann in ann_info['segments_info']])
if self.transforms is not None:
img, target = self.transforms(img, target)
return img, target
def __len__(self):
return len(self.coco['images'])
def get_height_and_width(self, idx):
img_info = self.coco['images'][idx]
height = img_info['height']
width = img_info['width']
return height, width
For panoptic segmentation, we would want the dataset to return the image and the segmentation mask when we call the __getitem__ method. We also return additoinal details like class label, bounding boxes, orignal size of the image as part of target along with the mask itself.
Also, if there are any transformations given, we apply those transformations on both the image and the mask.
As discussed in the Creating Custom Dataset for DETR post, the mask of the corresponding image should have the same name as the image with the suffix .png in the annotations folder.
# detr/datasets/construction.py
import datasets.transforms as T
normalize = T.Compose([
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
scales = [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
if image_set == 'train':
return T.Compose([
T.RandomHorizontalFlip(),
T.RandomSelect(
T.RandomResize(scales, max_size=1333),
T.Compose([
T.RandomResize([400, 500, 600]),
T.RandomSizeCrop(384, 600),
T.RandomResize(scales, max_size=1333),
])
),
normalize,
])
if image_set == 'val':
return T.Compose([
T.RandomResize([800], max_size=1333),
normalize,
])
DETR uses ImageNet standard-deviation and mean for the normalization.
For training dataloader, the transformations have Random Horizontal Flip and than it randomly selects between a Random Resize or collection of Random Resize, Random Size Crop and again Random Resize. The random resizing takes place at various scales of [480, 512, 544, 576, 608, 640, 672, 704, 736, 768, 800]
Whereas for validation, the images are resized to width of 800, with the height of max 1333 and than normalized.
A standard CNN is used to extract a compact feature representation of the image. Here a pre-trained ResNet50 model was used, and the features after the 5th block were extracted where the size of the image is compacted to H. W but with 2048 channels. Where H is H0/32, W is W0/32 and H0 & W0 are the initial Height and Width of the Image. A Conv2d is used to bring down the channels size from 2048 to 256

While the forward pass of the ResNet, the activation maps after each block of Res2(H0/4 x W0/4 x 128), Res3(H0/8 x W0/8x 256), Res4(H0/16 x W0/16 x 512) and Res5(H0/32 x W0/32 x 1028) are saved and set aside for the images which are to be used in the Panoptic segmentation down the line.
Sending to Transformer
The resultant compact features are now sent to the Transformer encoder-decoder architecture. But since Transformers expect sequential inputs, the compact features of size HxWx256 is flattened out to be HWx256 (in PyTorch, the tensor is 256xHxW, so after flattening to 256xHW, it is also transposed to HWx256)
In comparison to ViT where the Image is converted 196x768 embedding for 224x224 image, here the embedding we get is 196x256 (as after Res5 block, we have map size of 14x14 as HxW, so flattening it out gives 196 and we have 256 channels, giving embedding of 196x256).
As we discuees in the DETR part, Transformers are permutation equivariant, which in simpler terms means that the Transformers are not aware of the 2D structure of the image, permuting the inputs just permutes the outputs, and have no effect. So we will have to make sure to add some positional awareness to the inputs.
And this can be done in several ways, one way to do is adding learnable parameters to the input embeddings, where the networks will learn the positional encodings and the other way, as done in original Transformer, is adding some kind of fixed positional embedding like one-hot encoding or using some type of mathematical functions like sin functions with respect to the input patch position to generate the positional embedding. In DETR with empirical results the showed that the sin encodings had marginal better results than learnt embeddings, so these were used in the process.

After we get the Image embeddings, we can send to a Transformer Encoder, here we have 6 layers of encoders, where output of one encoder is sent as input to other, to increase the model capacity and improve training.
Since the transformers, work on sequence and maintain the sequence length, the input is a sequence of image patches and the output of all the encoders are also patches which can be again converted to form/shape of an image, so here after the image is encoded throught the encoder, we save the encoded image separately for further usage(which we will see soon in mask head part), and the sequence is sent to the decoder
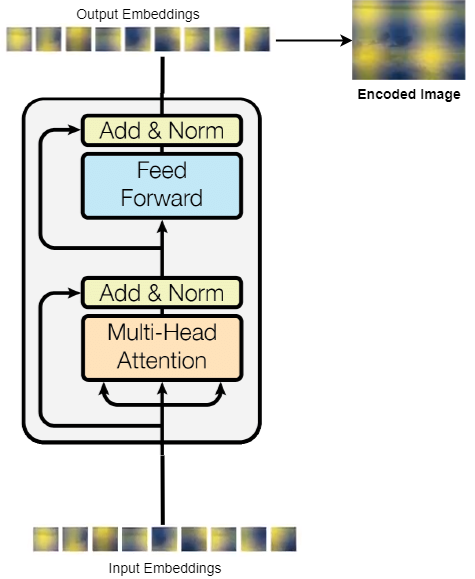
The sequence as discussed is sent to the decoder, but as a key and value, where as the query for the atetntion mechanis, comes from the Object Queries. The object queries here are fixed number of sequence of length N (here DETR used 100), where are initially initialized randomly, and the object queries intuitively works as a set entities asking the image(embeddings from encoder) regions about the presence of objects.
 If we see above, taken from the paper, they visualized 20 object queries, where each of the query, is getting information of presence of object at particular area, for differnet sizes of object, which is illustrated as three colors of green/red/purple. We can see that each object query has different area t concentrate for differnt object sizes.
If we see above, taken from the paper, they visualized 20 object queries, where each of the query, is getting information of presence of object at particular area, for differnet sizes of object, which is illustrated as three colors of green/red/purple. We can see that each object query has different area t concentrate for differnt object sizes.
Than we after the decoder layer, passes the final sequence from decoder to the Feed Forward Netwrok, to get the class_label and the bounding box of the object for each object, and since we added no object, now the model can predict 100 objects in the image, and if there are less than the model predicts as no-objects for those object queries
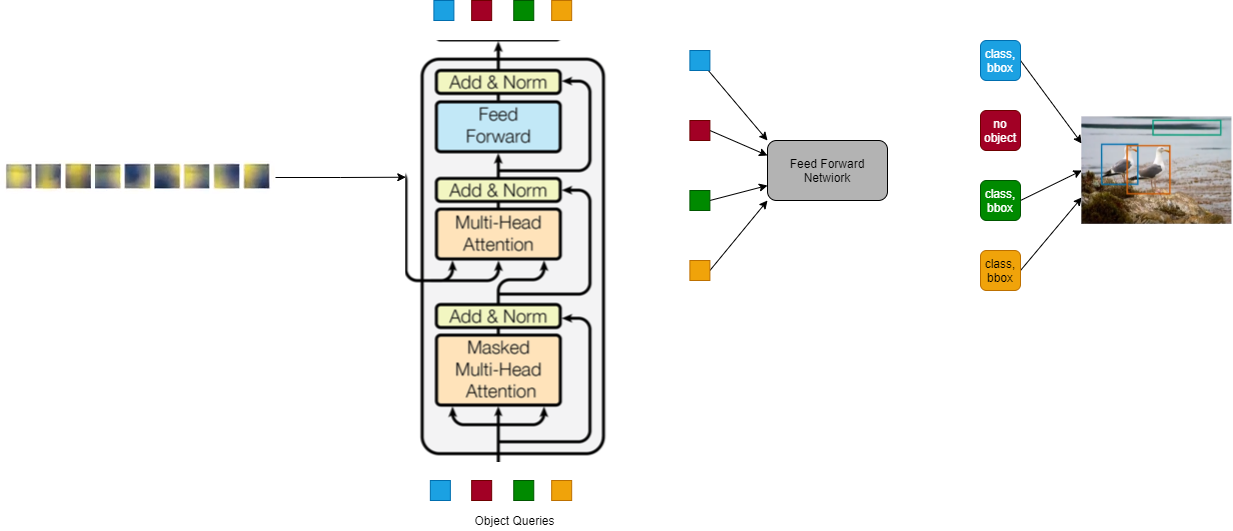
After the Bounding Box detection, now we add our mask head, which is used part of End-to-End model, to get Panoptic segmentation of the image.
This is acheived by doing attention of the obejct queries of the classes on the encoded image which we saved and set aside after the encoder transformer, and each object query after going through attention on the encoded image, will result in a mask for the class of the object query.
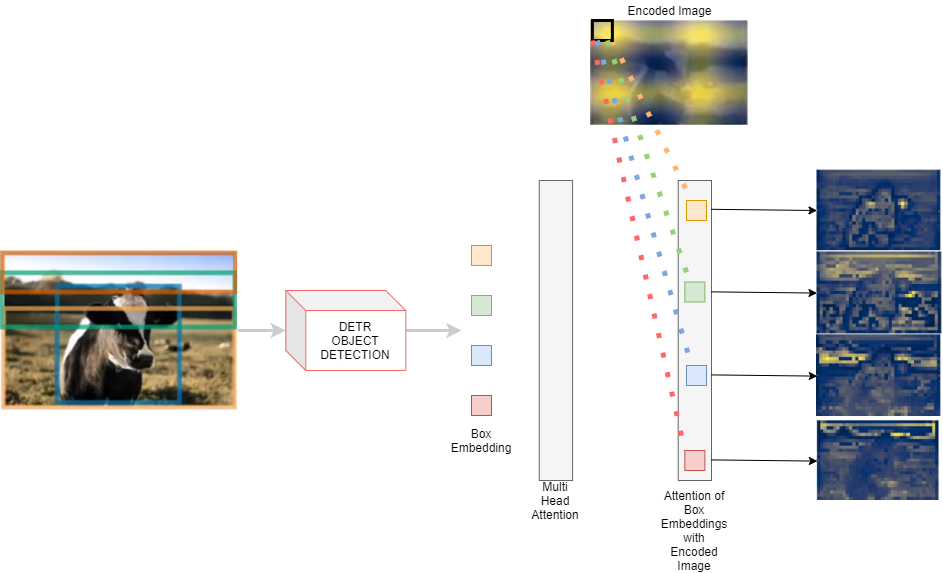
After getting these maps, which are of size H/32 x W/32, we would want to upscale the image and we now use an upsampling model, and also add the feature maps which we saved after every layer during the first step of ResNet forward pass.

And finally we can do Pixel wise Arg max to achieve the final segmentation map.




