Creating Custom Dataset using DETR
An approach for creating Dataset for Panoptic Segmentation using Pre Trained DETR.



What and Why?
We at TSAI wanted to train a Panpotic Segmentation Model(DETR) on a custom dataset. We decided to go ahead with Construction Classes and annotated the things of around 50 classes like grader, wheel loader, aac blocks etc.
While annotating we just annoatated the things, and left out stuff, as it would be way more tedious to annotate the stuffs like ground, grass, building etc.
We know existing Models are very well trained on COCO dataset, and we could levrage them to predict stuff classes in our images. So we went out and decided to use pre-trained DETR for Panoptic Segmentation to perform inference on our images and get this stuffs for our images.
In total we had 10k Images for all the classes combined, with very high imbalance, like 15 images for one class and on the other extreme 500+ images for other..
{
'aac_blocks': 0, 'adhesives': 1, 'ahus': 2, 'aluminium_frames_for_false_ceiling': 3,
'chiller': 4, 'concrete_mixer_machine': 5, 'concrete_pump_(50%)': 6, 'control_panel': 7,
'cu_piping': 8, 'distribution_transformer': 9, 'dump_truck___tipper_truck': 10,
'emulsion_paint': 11, 'enamel_paint': 12, 'fine_aggregate': 13, 'fire_buckets': 14,
'fire_extinguishers': 15, 'glass_wool': 16, 'grader': 17, 'hoist': 18,
'hollow_concrete_blocks': 19, 'hot_mix_plant': 20, 'hydra_crane': 21,
'interlocked_switched_socket': 22, 'junction_box': 23, 'lime': 24, 'marble': 25,
'metal_primer': 26, 'pipe_fittings': 27, 'rcc_hume_pipes': 28, 'refrigerant_gas': 29,
'river_sand': 30, 'rmc_batching_plant': 31, 'rmu_units': 32, 'sanitary_fixtures': 33,
'skid_steer_loader_(bobcat)': 34, 'smoke_detectors': 35, 'split_units': 36,
'structural_steel_-_channel': 37, 'switch_boards_and_switches': 38, 'texture_paint': 39,
'threaded_rod': 40, 'transit_mixer': 41, 'vcb_panel': 42, 'vitrified_tiles': 43,
'vrf_units': 44, 'water_tank': 45, 'wheel_loader': 46, 'wood_primer': 47
}
{
'building':48, 'ceiling':49, 'floor':50, 'food':51, 'furniture':52,
'ground':53, 'plant':54, 'raw_material':55, 'sky':56, 'solids':57,
'structural':58, 'textile':59, 'wall':60, 'water':61, 'window':62,
'thing':63
}
Mapping for each stuff category of COCO to their super category:
Categories to Super Categories
``` { 'cardboard': 'raw_material', 'paper': 'raw_material', 'plastic': 'raw_material', 'metal': 'raw_material', 'wall-tile': 'wall', 'wall-panel': 'wall', 'wall-wood': 'wall', 'wall-brick': 'wall', 'wall-stone': 'wall', 'wall-concrete': 'wall', 'wall-other': 'wall', 'ceiling-tile': 'ceiling', 'ceiling-other': 'ceiling', 'carpet': 'floor', 'floor-tile': 'floor', 'floor-wood': 'floor', 'floor-marble': 'floor', 'floor-stone': 'floor', 'floor-other': 'floor', 'window-blind': 'window', 'window-other': 'window', 'door-stuff': 'furniture', 'desk-stuff': 'furniture', 'table': 'furniture', 'shelf': 'furniture', 'cabinet': 'furniture', 'cupboard': 'furniture', 'mirror-stuff': 'furniture', 'counter': 'furniture', 'light': 'furniture', 'stairs': 'furniture', 'furniture-other': 'furniture', 'rug': 'textile', 'mat': 'textile', 'towel': 'textile', 'napkin': 'textile', 'clothes': 'textile', 'cloth': 'textile', 'curtain': 'textile', 'blanket': 'textile', 'pillow': 'textile', 'banner': 'textile','textile-other': 'textile', 'fruit': 'food', 'salad': 'food', 'vegetable': 'food', 'food-other': 'food', 'house': 'building', 'skyscraper': 'building','bridge': 'building', 'tent': 'building', 'roof': 'building', 'building-other': 'building', 'fence': 'structural', 'cage': 'structural', 'net': 'structural', 'railing': 'structural', 'structural-other': 'structural', 'grass': 'plant', 'tree': 'plant', 'bush': 'plant', 'leaves': 'plant', 'flower': 'plant', 'branch': 'plant', 'moss': 'plant', 'straw': 'plant', 'plant-other': 'plant', 'clouds': 'sky', 'sky-other': 'sky', 'wood': 'solids', 'rock': 'solids', 'stone': 'solids', 'mountain': 'solids', 'hill': 'solids', 'solid-other': 'solids', 'sand': 'ground', 'snow': 'ground', 'dirt': 'ground', 'mud': 'ground', 'gravel': 'ground', 'road': 'ground', 'pavement': 'ground','railroad': 'ground', 'platform': 'ground', 'playingfield': 'ground', 'ground-other': 'ground', 'fog': 'water', 'river': 'water', 'sea': 'water', 'waterdrops': 'water', 'water-other': 'water', 'things': 'things', 'water': 'water', 'window': 'window', 'ceiling': 'ceiling', 'sky': 'sky', 'floor': 'floor', 'food': 'food', 'building': 'building','wall': 'wall' } ```I = Image.open(<image_dir>/'images'/img['file_name']) # Sample Image
I = I.convert('RGB')

# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=['grader']); # Sample Category
imgIds = coco.getImgIds(catIds=catIds ); # Get Image Ids of all images containing the given category
img = coco.loadImgs(imgIds[np.random.randint(0,len(imgIds))])[0] #Random Image
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None) # Get annotation ids of all annotations for the img
anns = coco.loadAnns(annIds)
coco.showAnns(anns, draw_bbox=True)

from matplotlib.patches import Polygon
og_poly = []
for ann in anns: # For each annotation
poly = np.array(ann['segmentation'][0]).reshape((int(len(ann['segmentation'][0])/2), 2)) # Create Array from segmentation
poly = Polygon(poly) # Convert to matplotlib Polygon
og_poly.append(poly)
class_mask = np.zeros((og_w,og_h))
for op in og_poly:
cv2.fillPoly(class_mask, pts = np.int32([op.get_xy()]), color =(255)) # Paste our Annotations
plt.imshow(class_mask)

!git clone -q https://github.com/facebookresearch/detr.git #Facebook DETR
import sys
import os
sys.path.append(os.path.join(os.getcwd(), "detr/"))
# Load DETR trained on COCO for Panoptic Segmentation with ResNet101.
model, postprocessor = torch.hub.load('detr', 'detr_resnet101_panoptic', source='local', pretrained=True, return_postprocessor=True, num_classes=250)
model.eval()
print('Loaded!')
img = transform(I).unsqueeze(0) #Resize to 800 Width and Normalize
out = model(img) # Model Output
# compute the scores, excluding the "no-object" class (the last one)
scores = out["pred_logits"].softmax(-1)[..., :-1].max(-1)[0]
# threshold the confidence
keep = scores > 0.85
# Plot all the remaining masks
ncols = 2
fig, axs = plt.subplots(ncols=ncols, nrows=math.ceil(keep.sum().item() / ncols), figsize=(18, 10))
mask_log_list = []
for i, (attn_map,logit) in enumerate(zip(out["pred_masks"][keep], out["pred_logits"][keep])):
logit = logit.softmax(-1).argmax().item()
if logit > 92: # If stuff of COCO
det_id = meta.stuff_dataset_id_to_contiguous_id[logit]
logit = meta.stuff_classes[det_id]
mask_log_list.append((attn_map,logit))
axs.ravel()[i].imshow(attn_map, cmap="cividis")
axs.ravel()[i].axis('off')
fig.tight_layout()

As we can see, the model nicely predicts masks for each class. The predictions of the models are car, truck, sand, sky, person and tree.
The class maps are pretty darn good.
# the post-processor expects as input the target size of the predictions (which we set here to the image size)
result = postprocessor(out, torch.as_tensor(img.shape[-2:]).unsqueeze(0))[0]
# We extract the segments info and the panoptic result from DETR's prediction
segments_info = deepcopy(result["segments_info"])
# Panoptic predictions are stored in a special format png
panoptic_seg = Image.open(io.BytesIO(result['png_string']))
print(panoptic_seg.size)
final_w, final_h = panoptic_seg.size
# We convert the png into an segment id map
panoptic_seg = numpy.array(panoptic_seg, dtype=numpy.uint8)
panoptic_seg = torch.from_numpy(rgb2id(panoptic_seg))
# Detectron2 uses a different numbering of coco classes, here we convert the class ids accordingly
meta = MetadataCatalog.get("coco_2017_val_panoptic_separated")
for i in range(len(segments_info)):
c = segments_info[i]["category_id"]
segments_info[i]["category_id"] = meta.thing_dataset_id_to_contiguous_id[c] if segments_info[i]["isthing"] else meta.stuff_dataset_id_to_contiguous_id[c]
# Finally we visualize the prediction
v = Visualizer(numpy.array(I.copy().resize((final_w, final_h)))[:, :, ::-1], meta, scale=1.0)
v._default_font_size = 20
v = v.draw_panoptic_seg_predictions(panoptic_seg, segments_info, area_threshold=0)
cv2_imshow(v.get_image())

car, tree, sand, sky and person came out nicely. But the truck is pretty bad as the back area has got leaked into the right region.If we look at the above attention maps now, we see that the region between
tree and sand is not identified, the DETR post-processor spreads the masks of nearby class to regions where there are no predictions above the given threshold.
Even after pasting our grader annotation, there will be the truck annotation marked pixels in the image and the sand which is leaked.

And also the border of our annotations may still have the class as truck, so this masks will cause a problem, when we train our DETR.
DETR identifies objects using the edges, as shown in their example. The truck masks may case an issue, where our model may predict our grader as both grader and also truck.

# Taking only Stuff into Consideration
# Things of COCO is Void(id=0) for us
import itertools
import seaborn as sns
palette = itertools.cycle(sns.color_palette())
color_list = {}
combined_attn = np.zeros(out['pred_masks'].shape[2:] + (3,))
for attn_map, logit, class_id in mask_log_list:
color = (np.asarray(next(palette)) * 255)
color_list[class_id] = color
combined_attn[attn_map>0] = color
combined_attn = combined_attn.astype(np.int)
plt.imshow(combined_attn)
Instead, we can directly ArgMax on the attention maps of the stuff classes, ignoring the things classes of COCO, since we wouldn't want the same issue as mentioned above, and also avoiding the leakage of class by not using the inbuilt DETR post-processor.
Here the regions which are not predicted, will be marked with black pixels, which in COCO Dataset is void class

The mask with the BBox(class_id,area).
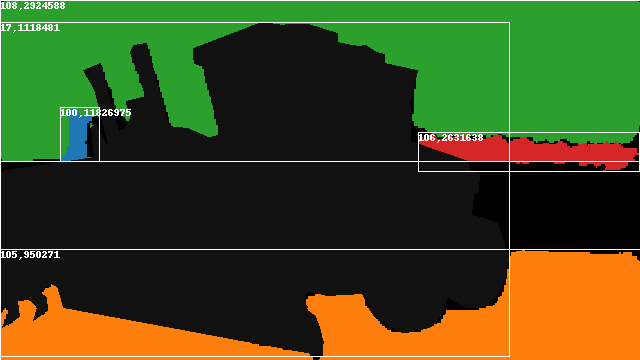
# Create Annotations of Each Class
def run_class(class_images_anns, class_name):
class_annotaion = []
class_image = []
class_color = CATEGORY_COLOR[class_name] # Get Color Tuple for the class
for img in tqdm(class_images_anns): # For each annotation in the JSON
# The Image annotations has .jpg whereas actual Image is png and vice-versa.
# try and except to get correct image accordingly
try:
I = Image.open(dataDir/class_name/'images'/img['file_name'])
except FileNotFoundError:
if img['file_name'].endswith('.jpg'):
I = Image.open(dataDir/class_name/'images'/img['file_name'].replace('jpg','png'))
elif img['file_name'].endswith('.png'):
I = Image.open(dataDir/class_name/'images'/img['file_name'].replace('png','jpg'))
# Convert any grayscale or RBGA to RGB
I = I.convert('RGB')
og_h, og_w = I.size
# Get Annotation of the Image
annIds = coco.getAnnIds(imgIds=img['id'], catIds=catIds, iscrowd=None)
anns = coco.loadAnns(annIds)
# Create Polygon for custom Annotation.
og_poly = gen_original_poly(anns)
# Get DETR output on our Image w.r.t COCO classes
trans_img = transform(I).unsqueeze(0)
out = model(trans_img.to('cuda'))
# Create Masks by stacking Attention Maps and Pasting our Annotation
# Excluding the functions definition for brevity. Can be found from colab link.
class_masks = generate_class_maps(out)
pred_mask, color2class = generate_pred_masks(class_masks, out['pred_masks'].shape[2:])
pred_mask = cv2.resize(pred_mask, (og_h, og_w), interpolation= cv2.INTER_NEAREST)
#Pasting Our Class on Mask
for op in og_poly:
cv2.fillPoly(pred_mask, pts = np.int32([op.get_xy()]), color = class_color)
#Convering Mask to ID using panopticapi.utils
mask_id = rgb2id(pred_mask)
# Final Segmentation Details
segments_info = generate_gt(mask_id, color2class, class_name)
# The ID image(1 Channel) converted to 3 Channel Mask to save.
img_save = Image.fromarray(id2rgb(mask_id))
mask_file_name = img['file_name'].split('.')[0] + '.png'
img_save.save(dataDir/class_name/'annotations'/mask_file_name)
# Appending the Image Annotation to List
class_annotaion.append(
{
"segments_info": segments_info,
"file_name": mask_file_name,
"image_id": int(img['id'])
}
)
return class_annotaion, class_image
for class_name in list_class: # Loop over all the classes names
annFile = <images_dir>/class_name/'coco.json' # Path to the annotations file of each class
coco = COCO(annFile) # Convert JSON to coco object (pycocotools.COCO)
cats = coco.loadCats(coco.getCatIds())
# get all images containing given categories, select one at random
catIds = coco.getCatIds(catNms=[class_name]);
imgIds = coco.getImgIds(catIds=catIds);
images = coco.loadImgs(imgIds)
try:
os.mkdir(<images_dir>/class_name/'annotations') # Create Annotations Folder for each Class
except FileExistsError as e:
print('WARNING!', e)
CLASS_ANNOTATION = run_class(images, class_name) # Generate Annotations for each class
FINAL_JSON = {}
FINAL_JSON['licenses'] = coco.dataset['licenses']
FINAL_JSON['info'] = coco.dataset['info']
FINAL_JSON['categories'] = CATEGORIES
FINAL_JSON['images'] = coco.dataset['images']
FINAL_JSON['annotations'] = CLASS_ANNOTATION
out_file = open(<images_dir>/class_name/'annotations'/f'{class_name}.json', "w")
json.dump(FINAL_JSON, out_file, indent = 4)
out_file.close()
COCO is a large-scale object detection, segmentation, and captioning dataset. COCO has several features with 80 object(things) classes, and 91 stuff classes for several tasks like captioning, segmentation, detection etc.
And it is the most widely used data as well as most widely used data format. So converting our annotations to the COCO format, would help us in levraging pre-built tools to create data pipelines to model.
File Structure
<dataset_dir>/
data/
<filename0>.<ext>
<filename1>.<ext>
...
annotations/
<filename0>.png
<filename1>.png
...
labels.jsonThe data folder has all the images, the images can be in image formats like JPG, JPEG, PNG.
The annotations folder has the images of the masks, for every image in the data folder, with the same name and .png extension. The stem name of the file should match with the image in the data.
The labels.json has 5 main keys, info, licenses, categories, images and annotations. This json file holds the data for the ground truth of the images. The format of the JSON can be varying as per the problem like object-detection, segmentation, keypoint-detection or image-captioning.
{
"info": info,
"licenses": [license],
"categories": [categories]
"images": [image],
"annotations": [annotation],
}The images, info and licenses remains same for all types, where as the annotations and categories format will differ.
info = {
"year": int,
"version": str,
"description": str,
"contributor": str,
"url": str,
"date_created": datetime,
}
image = {
"id": int,
"width": int,
"height": int,
"file_name": str,
"license": int,
"flickr_url": str,
"coco_url": str,
"date_captured": datetime,
}
license = {
"id": int,
"name": str,
"url": str,
}
Each object instance annotation contains a series of fields, including the category id and segmentation mask(optional if only Detection) of the object.
An enclosing bounding box is provided for each object (box coordinates are measured from the top left image corner and are 0-indexed). Finally, the categories field of the annotation structure stores the mapping of category id to category and supercategory names
annotation = {
"id": int, "image_id": int,
"category_id": int,
"segmentation": RLE or [polygon],
"area": float,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
categories = [{
"id": int, "name": str, "supercategory": str,
}]
For the panoptic task, each annotation struct is a per-image annotation rather than a per-object annotation. Each per-image annotation has two parts: (1) a PNG that stores the class-agnostic image segmentation and (2) a JSON struct that stores the semantic information for each image segment
- To match an annotation with an image, use the image_id field (that is annotation.image_id==image.id).
- For each annotation, per-pixel segment ids are stored as a single PNG as the same name as image.
- Each segment (whether it's a stuff or thing segment) is assigned a unique id.
- Unlabeled pixels (void) are assigned a value of 0. Note that when you load the PNG as an RGB image, you will need to compute the ids via ids=R+G*256+B*256^2.
- In annotation file. The segment_info.id stores the unique id of the segment and is used to retrieve the corresponding mask from the PNG (ids==segment_info.id).
- Finally, each category struct has two additional fields: isthing that distinguishes stuff and thing categories and color that is useful for consistent visualization.
annotation = {
"image_id": int,
"file_name": str,
"segments_info": [segment_info],
}
segment_info = {
"id": int,
"category_id": int,
"area": int,
"bbox": [x,y,width,height],
"iscrowd": 0 or 1,
}
categories = [{
"id": int,
"name": str,
"supercategory": str,
"isthing": 0 or 1,
"color": [R,G,B],
}]